

The world needs an AI lab — for Data
Why is AI so good at some things and so bad at others? The answer is the data.


America | Tech | Opinion | Culture | Charts
Today’s post is by Bobby Samuels, CEO of Protege.

The frontier of artificial intelligence is jagged.
If you’re a serious user of frontier AI systems, that statement shouldn’t surprise you. In some domains, most prominently in coding, AI is truly stunning and already superhuman. But ask AI to navigate a multi-step customer workflow, or to interpret a complex medical scan, and you’ll find that at a certain level of complexity it inevitably breaks down.
Why is that? The model is the same across different dimensions: the same architecture running on the same hardware. What changed? Why is AI so good at some things and so bad at others?
The answer is the data. Some fields—like coding—benefit from reams of rich, well-structured, high-quality data, in large parts because the domain is extremely well-defined: everything you need to know is right there, in the code. But many other fields, like medicine, don’t.
We call it the data gap.
This data gap is one of the most important problems in AI today, and solving it is perhaps the most underrated bottleneck to rapid AI progress. And it’s why I am making a big announcement today. My company Protege is announcing DataLab: a dedicated research institution whose mission is to close the data gap that is holding back AI progress.
DataLab at Protege is not a data broker or a human-feedback body shop. It is a lab for AI data in the same way that OpenAI or Anthropic are labs for AI models, or that Nvidia Research is a lab for GPUs: the same rigor, the same research caliber, and the same scientific ambition. All this, applied for the first time at scale, to the data layer on which all AI progress depends.
What does that mean in practice? In brief, it means building multimodal healthcare benchmarks that reflect actual clinical scenarios, not generic medical Q&A, so that a model assisting in a cancer tumor board can be evaluated against the complexity it will really face.
It means developing frameworks for agentic task selection: identifying which real-world workflows are worth training AI agents on, and which are distractions.
It means creating “FICO scores” for AI data: standardized methods to quantify dataset quality and benchmark reliability across domains. And it means conducting research on dataset contamination, factuality, and representational bias that the entire AI field can build on.
We are building the data lab that AI needs to smooth out and push forward the jagged frontier of intelligence.



Data is the neglected bottleneck to AI progress
To understand why the world needs an AI data lab so badly, we should think about what is currently limiting AI progress.

There are three fundamental bottlenecks for AI progress: better algorithms, better chips on which to run those algorithms, and better data for those algorithms to train on. For the last few years of tremendous progress in AI to continue or even accelerate, we need to be pushing on all three at once.
We’re certainly pushing on algorithmic progress already. We have dedicated labs—OpenAI, Anthropic, Google DeepMind, and others—that employ thousands of researchers pushing the boundaries of what models can do. These labs employ many of the most talented engineers and scientists in the world, and they’ve made massive strides in the last few years.
And we’re pushing on compute. Nvidia and its competitors are waging a relentless campaign to build more powerful hardware, and billions of dollars flow into the infrastructure to run it as efficiently as possible. Both models and chips each have their own ecosystem of world-class researchers, massive R&D budgets, and a shared sense of mission.
But what about the third bottleneck—the data that AI models use to learn and improve?
Right now, there’s no leading lab for AI data: no institution that combines large-scale data access with rigorous data research, curation, and experimentation. There are smaller groups doing valuable data research and advising the big AI labs. But nobody has yet built an institution that does both, and at scale.
And that’s a really serious problem. Because while models and chips have received a huge amount of attention, researchers at every frontier lab will tell you the same thing: high-quality data is the bottleneck for AI progress.
Not compute, not architecture, but data.
AI progress in 2026 and beyond will require the full breadth and depth of real-world data: the data generated by people living their normal lives, from healthcare to video to audio, and much, much more. No two datasets are the same. Somebody has to build the institution that can work with that data at the scale and rigor that AI progress demands. That is why we’re building DataLab.
Every AI breakthrough needs a breakthrough dataset
Why is it so important that we have a leading institution for AI data?
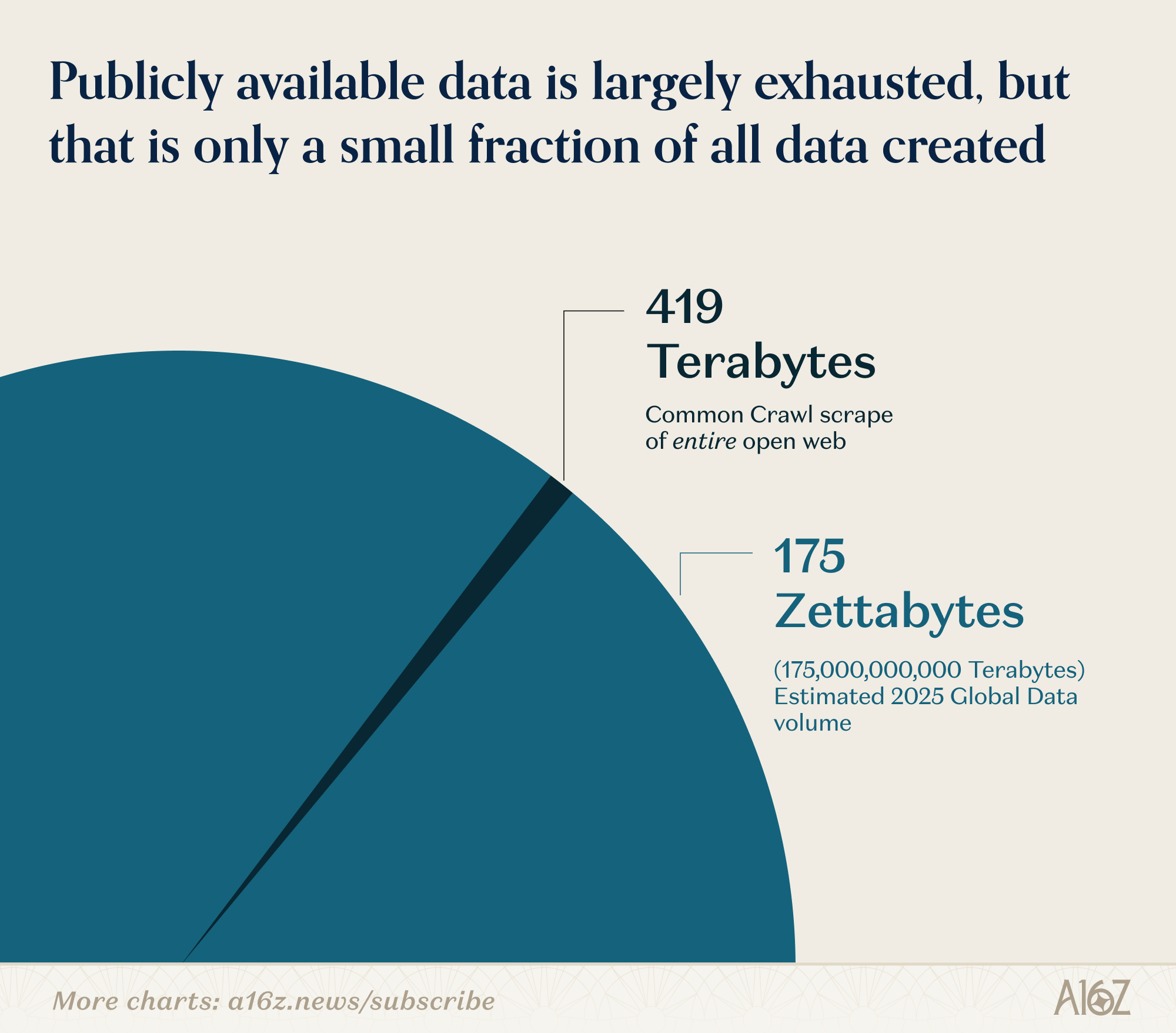
It’s not just that the labs have scraped the entire internet and now need higher-quality data. That’s true, but it’s only a part of it. The reality is bigger than that: in the entire history of AI, every major leap in capabilities has been built on a corresponding leap in the available data.
Take Yann LeCun’s development of convolutional neural networks in the late 1980s. LeCun’s work on CNNs was a revolution—but that algorithmic breakthrough required a data breakthrough first. His convolutional neural networks needed something to see. And that something came from the U.S. Postal Service, which had spent years on a tedious, unglamorous project: photographing handwritten ZIP codes from real envelopes, then having humans carefully label each digit. The result was a dataset of nearly 10,000 images—a tiny corpus by today’s standards, but unprecedented at the time. Without that dataset, LeCun’s architectural innovation would have remained a theoretical curiosity: the algorithm needed the data to prove itself. And the data needed to exist before anyone knew what it would unlock.
Or take AlexNet, which kickstarted the deep learning revolution in 2012. The work that Geoffrey Hinton, Alex Krizhevsky, and Ilya Sutskever did was legendary. But the breakthrough wasn’t just AlexNet: it was AlexNet trained on ImageNet, the massive visual dataset that Fei-Fei Li and her team spent years painstakingly assembling. Yes—years. Li began her project in 2006; it took until 2009 for the first version to be released. That meant three years of organizing, cleaning, and labeling more than 3.2 million images across thousands of categories, using a combination of Amazon Mechanical Turk workers and her own graduate students. The discovery that scaling up a dataset led to much better models couldn’t have been made if not for the people who spent years actually scaling up the dataset.
And this goes on and on. The entire large language model paradigm, for example, is only possible because the internet produces an ocean of text data. You can tell the whole story of the AI revolution of the last few years as a story of discovering new datasets and taking full advantage of them.
So who’s building the next hundred ImageNets? Who is doing for today’s frontier challenges what Fei-Fei Li did for computer vision: investing huge amounts of time, energy, and thought into assembling datasets that will unlock the next generation of AI capabilities?
Because of how much progress we’ve made in the last few years, the data challenges we have in front of us are genuinely challenging and new. There’s no established playbook for identifying high-quality audio to train text-to-speech models. There’s no consensus on what a gold-standard dataset looks like for training AI agents to perform real-world tasks with many steps in key industries. There’s no off-the-shelf solution for building multimodal healthcare benchmarks that reflect actual clinical scenarios.

These are research problems, hard ones, and they deserve to be treated that way.
The data gap is worse than you think
Talk to any researcher at a frontier AI lab, and they’ll describe the same problem: their models are only as good as their data, and the data just isn’t good enough. They know exactly which capabilities they want to build, but the datasets to get there either don’t exist, aren’t structured properly, or can’t be trusted.
We know from our experiences working with almost every leading AI lab today: real-world data across industries is fragmented, proprietary, and almost never AI-ready by default. The gap between what model researchers need and what they actually get is enormous.
Why? It is not actually from the lack of data. The core issue is actually around the lack of AI data expertise.
This breaks down into a few key areas. The first is capacity. Across all the domains where AI needs to improve, from healthcare to multilingual audio to agentic work, there simply aren’t enough top-caliber teams in the world actually doing the demanding work of building the next ImageNet-type datasets. The “sexy” problems lie elsewhere in the AI stack.
The second problem is attention. The researcher designing the model shouldn’t be the same person building the dataset. Model research and data research are different disciplines with different skills, and the field needs dedicated institutions for each one. We don’t ask GPU architects to design the models that run on their chips; it makes equally little sense to ask model researchers to build the datasets that their models train on.
And the third problem is translation. A procurement team at a major lab might get a request for something like “nature footage” or “medical conversations.” But what do those actually mean to the researchers that are training or evaluating with the data? The specifics that determine whether a dataset will be useful or useless get lost in translation between the scientists who need the data and the teams responsible for sourcing it, often because they’re forced to source that data from outside data holders whose interest is commercial, not scientific.
This is also why the existing ecosystem of data companies—the RLHF gyms, annotation shops, and labeled-data vendors—doesn’t close the gap on their own. These organizations produce what you might call “manufactured data”: commercially produced datasets where human workers complete clearly defined tasks, like rating model outputs or assessing liability from contractual language. That work is valuable for reinforcement learning on well-scoped problems.
But manufactured data, by its very nature, lacks the nuance and complexity of real, lived experience. The hardest frontiers in AI require real human activity data: the data generated by people’s daily lives and the complex operations of organizations, captured in software systems and recordings of actual interactions. That data is proprietary, fragmented, multimodal, and almost never AI-ready. Turning it into something a frontier model can learn from is not just a sourcing exercise, but is fundamentally a research problem.
The essential problem is that important data decisions are still treated as procurement problems rather than research problems. Organizations hire vendors to deliver datasets the same way they’d order office furniture. The implicit assumption is that data is a commodity—interchangeable, fungible, and not worth serious scientific attention.
The history of machine learning tells us that better data beats better algorithms. The choice of which data to include, how to structure it, what to filter out: these simple decisions shape everything downstream. Getting them right requires researchers of the same caliber as those at AI labs, researchers who can think at the margin.
What does this next datapoint buy us? What do we lose chasing the wrong dataset? What does the right dataset even look like?
What a frontier AI data lab looks like
We’re building DataLab at Protege to close this gap: a scientific institution at the intersection of three functions that have never been combined at this scale.
First: a scientific arm that speaks the language of frontier model research. We navigate the same difficult and often ambiguous technical discussions as the PhD researchers at the leading AI labs—because that’s who our people are. We’re the intellectual counterparts of the people building the models, and we engage with them as peers on questions of data quality, dataset design, and evaluation methodology. When a lab is deciding what data to train on next, we’re the trusted partner in that conversation.
Second: a dataset builder that creates AI-ready datasets with methodological rigor. We don’t just source data: we design datasets the way you’d design an experiment: with clear hypotheses about what the model needs to learn, rigorous protocols for collection and annotation, and systematic validation that the final product actually does what it’s supposed to do.
And third: a research leader that sets the standard for the field. We publish findings, create benchmarks, and identify data gaps. The data layer of AI deserves its own research agenda, and we’re building it.
Here’s what that looks like in practice. We’ve already released multimodal healthcare evaluations and benchmarks that reflect the actual complexity of healthcare AI: a model that’s going to assist in clinical decision-making can’t be evaluated with a generic medical Q&A benchmark. And we’re developing frameworks for agentic task selection—identifying what data is needed to unlock AI agents, which tasks are actually worth solving, and which are distractions. This effort brings together economists, machine learning researchers, and domain experts in a multidisciplinary collaboration. In parallel, we’re advancing a research agenda focused on evaluating dataset factuality and groundedness, as well as developing context-aware methods for robust de-identification. We’re also building quality measurement tools for the next generation of text-to-speech models. And we’re tackling the hard problems of international data representation, selection, and bias head-on.

And, perhaps most importantly, we’re developing what we think of as “FICO scores” for AI data: a family of methods, tailored to different data types and use cases, that systematically quantify the quality of datasets and the reliability of model evaluations.
Just as a FICO score gives lenders a standardized, trustworthy measure of creditworthiness, we’re building the equivalent for AI: objective scores that tell researchers how much they should trust a given dataset or benchmark result. The scoring system for a multilingual audio corpus will look different from the one for an agentic task dataset or a clinical imaging benchmark, because dimensions of quality differ across domains. But the underlying principle is the same: you can’t improve what you can’t measure.
Consider data scaling laws—the marginal intelligence return from a given volume of data. Those returns differ dramatically across the training stack. Understanding which attributes of a dataset a model is actually relying on can explain why, in some cases, 10×-ing the data yields only limited gains. Contaminated benchmarks—those already present in the training data—provide no new insight and can actively harm progress.

These aren’t procurement decisions or matters of taste. They are fundamental statistical questions—which is why benchmarks and evaluations, which are increasingly used as the gate between a model in testing and a model deployed in the real world, need to be built with scientific rigor. If the benchmark itself isn’t robust enough for the use case that the model is intended for—if you’re using a generalist medical Q&A eval to sign off on a model that will be used in a multimodal cancer tumor board—then the gate isn’t doing its job.
And when the gate fails, the consequences can be severe. If the AI powering a cancer detection tool is measured with data it was trained on—and thus already had the answers to—then it cannot possibly be deployed with confidence in clinical settings. This kind of rigor isn’t glamorous; but it’s the foundation that everything else depends on.
We work with the major AI labs, providing critical data input and expertise on their hardest problems. We ask the difficult questions: about data warts, contamination, representational gaps, and the technical details that get overlooked when data is treated as an afterthought. Our goal at DataLab is simple: to set the data direction for the future of AI.
But we know that this work is bigger than any single organization. What the field needs is an entire ecosystem of AI data labs, each with a different focus and angle, approaching the problem with the same intensity and resources that we’ve devoted to hardware accelerators and algorithms. DataLab at Protege is only the beginning of that movement.
If you’re a researcher at a frontier lab who’s frustrated that data bottlenecks are slowing your work—talk to us. If you’re an academic working on ML approaches to remedy the imperfections of real-world data—collaborate with us. If you’re working on data problems in any domain, we want to hear from you.
The models have their labs. The chips have their fabs. It’s time that data got the same treatment. Because the next era of AI progress depends on it.



This newsletter is provided for informational purposes only, and should not be relied upon as legal, business, investment, or tax advice. Furthermore, this content is not investment advice, nor is it intended for use by any investors or prospective investors in any a16z funds. This newsletter may link to other websites or contain other information obtained from third-party sources - a16z has not independently verified nor makes any representations about the current or enduring accuracy of such information. If this content includes third-party advertisements, a16z has not reviewed such advertisements and does not endorse any advertising content or related companies contained therein. Any investments or portfolio companies mentioned, referred to, or described are not representative of all investments in vehicles managed by a16z; visit https://a16z.com/investment-list/ for a full list of investments. Other important information can be found at a16z.com/disclosures. You’re receiving this newsletter since you opted in earlier; if you would like to opt out of future newsletters you may unsubscribe immediately.
Such a great post. So many thoughts!
1. This post distills years of intuition around the role of data in a short read.
2. Curious if “golden data sets” are still better better than “large data”. If you can’t have quality and quantity, is small quantity enough?
3. Personally, I think agentic stablecoin payments are going to serve as a strong signal (label?) for high quality content in the future. The de-slopifier.
4. It’s early, but pre-construction is where I believe the next large untapped data opportunity will lie.
Loved this take, feels very relevant right now. The way you’ve framed it makes the whole topic feel a lot more practical than theoretical.